Introducción a la programación con Python¶
Jupyter Notebook 1 para Técnicas Experimentales 2021-1¶
Facultad de Ciencias, UNAM¶
El material de este "notebook" está basado en la lección Programming with Python de los Software Carpentry Workshops, publicada bajo la licencia Creative Commons - Attribution License. Traducción y modificaciones por Karina Ramos Musalem.
Antes de empezar¶
Al terminar esta semana (intro01_python):
- Sabrán qué es un jupyter notebook, cómo se abre y cómo se usa.
- Sabrán qué es un arreglo de numpy, los índices de un arreglo y el orden de los arreglos.
- Aprenderán a calcular max, min, promedio y desviación estándar de un arreglo.
- Aprenderán a abrir un archivo de datos tabulados (csv).
- Graficarán un arreglo usando matplotlib, y aprenderán a editar los nombres de los ejes, título, etc.
Jupyter notebooks¶
Los Jupyter notebooks son una aplicación web de código abierto que combinan celdas de código, figuras, ecuaciones y texto. Soportan varios lenguajes de programación como Python, R y Julia entre otros. Se abren en cualquier navegador (explorer, firefox, safari, chrome,...). Ojo: no necesitas estar conectado a internet para abrir un notebook; el notebook corre localmente en tu computadora y solo utiliza al navegador para ser ejecutado y que puedas interactuar con él.
Puedes cambiar el tipo de celda en la barra del enabezado seleccionando "code" para código y "markdown" para texto. Markdown es un es un lenguaje de marcado que tiene como objetivo facilitar la tarea de dar formato a un texto mediante el uso de solo algunos caracteres. Aquí hay una guía de uso en español. Es muy común para escribir en internet y para tomar notas.
Si das doble click en esta celda de texto verás cómo se da formato al texto. Los encabezados se denotan con #,##, ###, etc, texto en negritas entre doble asterisco, itálicas entre asteriscos, etc.
Para ejecutar una celda da click en el botón Run en la barra de herramientas o puedes oprimir Shift+Enter. Esto último es lo más rápido, y con la práctica te acostubrarás a hacerlo en automático.
Algo importante que considedad es el orden en el que ejecutas las celdas. Dspués de ejecutar una célda de códico aparece un nímero del lado izquierdo que indica el orden en el que has ejecutado las celdas. La primera celda ejecutada tiene un 1, la segunda 2 y así sucesivamente. Si vuelves a ejecutar una celda, el número cambiará. Esto tendrá más sentido una vez que empecemos.
1.1 Variables¶
Cualquier intérprete de Python pude usarse como una calculadora (intérprete=jupyter notebook, python en la terminal, ipython, etc)
3 + 5 * 4
Esto está bien pero no es muy interesante. Para poder hacer algo útil con los datos debemos asignar su valor a una variable. En Python, asignamos un valor a una variable usando el signo de igual =. Por ejemplo, para asignar el valor 30 a la variable peso_kg, ejecutamos el comando:
peso_kg = 30
De ahora en adelante, cada vez que usemos peso_kg, Python sustituirá el valor que le asignamos. En otras palabras, una variable es un "nombre" para un valor (en verdad una variable es un "lugar" en la memoria de la computdora, pero esa es otra historia.)
En Python, los nombres de las variables:
- pueden incluir letras, digitos y guión bajo,
- no pueden empezar con un dígito,
- son sensibles a mayúsculas y minúsculas.
Por ejemplo:
peso0es un nombre válido pero0pesono lo es,pesoyPesoserán distintas variables.
1.2 Tipos de datos o variables¶
Python conoce distintos tipos de datos. Los tres más comúnes son:
- números enetros,
- números decimales (floating point numbers) y
- strings.
En el ejemplo anterior, la variable peso_kg contiene el valor entero 30. Para crear una variable con valor decimal, podemos ejecutar:
peso_kg = 30.0
y para crear una cadena o string añadimos comillas dobles o simples alrededor de algún pedazo de texto:
peso_kg_texto = 'peso en kilogramos:'
1.3 Uso de las variables¶
Para mostrar el valor de una variable en la pantalla podemos usar la función print:
print(peso_kg)
Podemos mostrar varias cosas a la vez con un solo comando print:
print(peso_kg_texto, peso_kg)
Aún mejor, podemos hacer operaciones aritméticas entre variables dentro del comando print:
print('El peso en libras es:', 2.2 * peso_kg)
Nota que el comando anterior NO cambió el valor de peso_kg:
print(peso_kg)
Para cambiar el valor de peso_kg, debemos asignarle un nuevo valor usando el signo igual =:
peso_kg = 65.0
print('El peso en kg ahora es:', peso_kg)
Asignar un valor a una variable no cambia el valor de otras variables. Por ejemplo, si creamos una variable peso_lb como:
peso_lb = 2.2 * peso_kg
print(peso_lb)
y después cambiamos el valor de peso_kg:
peso_kg = 80.0
print('peso_kg es: ', peso_kg, 'y peso_lb es: ', peso_lb)
El valor de peso_lb no cambia. Esto es porque las variables no "recuerdan" de dónde viene su valor. Éste no se actualiza si cambiamos peso_kg.
Pon en práctica lo que aprendiste¶
- ¿Qué valores tienen las variables
temperaturaysalinidaddespués de ejecutar los comandos mostrados en la siguente celda? - Comprueba tu respuesta ejecutando la celda siguiente y añadiendo el comando
printcon los argumentos necesarios para mostrar el valor detemperaturaysalinidad.
Nota: El argumento es la información que necesita el comando para ser ejecutado. Los argumentos son las variables o valores entre paréntesis después del comando. Por ejemplo, en print('Hola mundo'), el argumento del comando print es 'Hola Mundo'.
temperatura = 20.5
salinidad = 50.2
temperatura = temperatura * 2.0
salinidad = salinidad - 20
# Añade el comando `print` en esta celda para desplegar el valor
# de las variables temperatura y salinidad. Después ejecuta la celda.
print('El valor de temperatura es: ', temperatura)
print('El valor de salinidad es: ', salinidad)
- ¿Qué imprimirá el siguente progama?
R: Marie Tharp
Comprueba tu respuesta ejecutando la celda.
primero, segundo = 'Marie', 'Tharp'
tercero, cuarto = primero, segundo
print(tercero, cuarto)
1.4 En resumen¶
- Las variables básicas de Python son de tipo entero, decimal (floats) o cadenas (strings)
- Usa
variable = valorpara asignar un valor a una variable y guardarlo en memoria. - Las variables se crean conforme se requieren cuando se les asigna un valor.
- Usa
print(algo)para mostrar o imprimir el valor dealgo.
2. Análisis de datos en Python usando un ejemplo¶
Aunque Python cuenta con muchas herramientas poderosas y generales, hay herramientas especializadas, construídas a partir de las unidades básicas de Python, que viven dentro de bibliotecas que pueden ser invocadas cuando se requieran.
Una biblioteca (library) es una familia de unidades de código (funciones, clases, variables) que implementan un conjunto de tareas relacionadas entre sí.
Preguntas a responder¶
¿Cómo puedo procesar datos tabulados en Python (separados por espacios, comas, etc.)?
Objetivos¶
- Entender qué es una biblioteca de Python (library, a veces dicen librería en los foros) y para qué se usa.
- Importar una biblioteca de Python y usar las funciones que contiene.
- Leer datos de un archivo de texto y usarlos en un programa.
- Seleccionar valores individuales y subsecciones de los datos.
- Realizar operaciones con arreglos de datos.
2.1 Abrir datos desde Python¶
Para empezar a analizar datos, debemos "cargarlos"o "subirlos" a Python. Podemos hacer eso utilizando la biblioteca NumPy llamada así por Numerical Python. En general, usamos esta biblioteca cuando queremos hacer operaciones sofisticadas (y no tanto) con muchos números, especialmente si tenemos matrices o arreglos. Para decirle a Python que queremos empezar a usar NumPy debemos importar NumPy:
import numpy
Importar una biblioteca es como sacar un instrumento de laboratorio de la bodega para tenerlo a la mano. Las bibliotecas nos permiten usar funciones adicionales a las del paquete básico de Python. Así como en el laboratorio, importar demasiadas bibliotecas puede complicar o frenar tus programas -- así que solo importa lo que necesites.
Una vez que importamos la biblioteca numpy podemos pedirle que lea nuestro archivo de datos:
numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
El comando numpy.loadtxt(...) es un llamado que le pide a Python que ejecute la función loadtxtque pertenece a la biblioteca numpy. Esta notación se usa en todo Python: la cosa que aparce después del punto está contenida en la cosa antes del punto.
numpy.loadtxt tiene dos parámetros o argumentos: el numbre del archivo que vamos a leer y el delimiter que nos dice cuál es el caracter que separa los valores en cada línea. Ambos parámtros deben ser tipo string, por lo que los rodeamos con comillas.
Como no le hemos dicho a Python que haga algo con el output o resultado de la función, el notebook imprime los datos por default. Solo muestra algunas líneas y columnas (usa ... para omitir algunos elementos cuando el arreglo es muy grande). Para ahorrar espacio, python no muestra los ceros después del punto decimal (1. en vez de 1.0).
Nota: Atajo para importación de bibliotecas¶
En esta lección usamos la sintaxis import numpy para importar NumPy. Después llamamos a las funciones dentro de numpy como numpy.función. Es posible utilizar un nombre mas corto para numpy usando la sintáxis import numpy as np. Así, llamamos a las funciones dentro de numpy como np.función. Esta es una práctica común, y resulta en líneas de código más cortas, especialmente si el nombre de la biblioteca es muy largo. Puedes usar la sintáxis que prefieras pero ten cuidado de usar nombres cortos que sean descriptivos y tengan sentido para otros. Es decir, no abrevies numpycomo n, eso puede ser confuso.
Volviendo a los datos, nuestra ejecución de numpy.loadtxt leyó los datos pero no los guardó en memoria. Para ello debemos asignar el arreglo de datos a una variable. Ejecutemos de nuevo numpy.loadtxt asignando los datos a una variable:
data = numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
Esto no produce ningún output porque asignamos el output a la variable data. Para corroborar que se guardaron los datos, imprimimos el valor de la variable data:
print(data)
Ahora que tenemos los datos en memoria, podemos manipularlos. Primero, preguntemos qué tipo de cosa es data:
print(type(data))
El output nos dice que dataes un arreglo de numpy N-dimensional.
Los datos corresponden a la precipitación anual en la estación Meteorológica PEMBU del Centro de Ciencias de la Atmósfera de la UNAM (CCA). Las filas de este arreglo correponden a distintos años (2011-2018) y las columnas a la precipitación promedio por mes del año. La precipitación está medida en milímetros de lluvia.
NOTA: Un arrelgo de NumPy contiene uno o más elementos del mismo tipo. La función typesolo nos dice que la variable dataes un arreglo de NumPy pero no te dice el tipo de las cosas dentro del arreglo. Podemos conocer el tipo de los datos contenidos en data utilizando:
print(data.dtype)
Esto nos dice que los elementos del arreglo de NumPy data son de tipo decimal o float.
Con el siguiente comando podemos conocer la forma o tamaño del arreglo:
print(data.shape)
Esto nos dice que el arreglo data contiene 8 filas y 12 columnas. Hemos creado la variable data para guardar la información de la precipitación mensual, pero no solo creamos eso; también creamos automáticamente información acerca del arreglo llamada miembros o atributos. Esta información adicional describe a datade la misma forma que un adjetivo describe a un sustantivo. data.shapees un atributo de data que describe las dimensiones de data. Usamos la misma notación de punto para los atributos de variables que para las funciones en bibliotecs porque tienen la misma relacion todo-parte.
Si queremos seleccionar o sacar un solo número del arreglo, debemos proporcionar un índice entre paréntesis cuadrados [] después del nombre de la variable. Nuestros datos de precipitación tienen dos dimensiones, por lo que debemos porporcionar dos índices para referirnos a un valor específico:
print('el primer elemento en data es:', data[0,0])
print('el elemento en la mitad de data es:', data[4,6])
Tal vez te sorprenda la expresión data[0,0]para elegir el elemento en la primera columna primer renglón. Los lenguajes de programación como Fortran, Matlab y R empiezan a contar desde 1 porque eso hacen los humanos. Los lenguajes en la familia C (como C++, Java, Perl y Python) cuentan desde 0 porque eso representa el incremento desde el primer valor en el arreglo (el segundo valor está desplazado por un índice desde el primer valor). Esto es más cercano a la forma en que las computadoras repesentan arreglos (Aqui hay una entrada del blog de Mike Hoye si les interesa saber más sobre esto).
Como resultado, si tenemos un arreglo de MxN en Python, sus índices van del 0 a M-1 en la primera dimensión y de 0 a N-1 en la segunda. Lleva un rato acostumbrarse, pero pueden pensar que la regla es que el índice es el número de pasos tenemos que saltar desde el comienzo hasta el elemento que queremos.

Otra nota al respecto. Python muestra el elemento con índices [0,0]en el extremo superior izquierdo. Esto es consistente con la forma en que dibujamos matrices en matemáticas, pero distinto a las coordenadas Cartesianas. Los índices son (fila, columna).
2.2 Seleccionar porciones o "rebanadas" de datos¶
Usando índices como [3,8] seleccionamos un solo elemento del arreglo, pero podemos seleccionar secciones o rebanadas (slice en inglés) también. Por ejemplo, podemos seleccionar los primeros 5 meses de datos (columnas) de los primeros 4 años (filas):
print(data[0:4, 0:5])
La selección o rebanada 0:4 quiere decir "Empieza en el índice 0 y selecciona hasta, pero sin incluir, el índice 4". De nuevo, lleva un poco de tiempo acostumbrarse a este "hasta, pero no incluyas", pero la regla es que la diferencia entre los límites inferior y superior es el número de valores en la rebanada.
Las rebanadas no tienen que empezar en 0:
print(data[5:8, 1:9])
Además, no es necesario incluir los límites superior e inferior de la selección. Si no incluimos límite inferior, Python usa el 0 como default; si no incluimos el superior, Python selecciona hasta el último elemento de ese eje; si no especificamos ningún límite (:), Python selecciona todo el eje:
rebanada = data[:3, 8:]
print('la rebanada es:')
print(rebanada)
El ejemplo anterior selecciona las filas 0 a 2 y las columnas 8 al final del arreglo.
2.3 Analizar los datos¶
NumPy tiene muchas funciones útiles que toman al arreglo como input para realizar alguna operación con sus valores. Si queremos encontrar el promedio anual de precipitación usando todos los años, le podemos pedir a NumPy que compute el promedio de data:
print(numpy.mean(data))
mean (mean es promedio en inglés) es una función que toma un arreglo como argumento.
Pequeño paréntesis: No todas las funciones necesitan un input para producir un output. Por ejemplo, la función para checar la hora no requiere input:
import time
print (time.ctime())
Aunque la función no requiera input, debemos escibir () para decirle a Python que ejecute la función.
De vuelta a los datos, usemos otras tres funciones para obtener algunos valores descriptivos de la precipitación. Además usaremos la asignación múltiple, que es una forma conveniente de asignar varios valores en una línea de código:
maxval, minval, stdval = numpy.max(data), numpy.min(data), numpy.std(data)
print('precipitación máxima (mm):', maxval)
print('precipitación mínima (mm):', minval)
print('desviación estandar (mm):', stdval)
Aquí asignamos el output de numpy.max(data) a la variable maxval, el valor de numpy.min(data) a la variable minval, etc.
TIP:¶
Si estas trabajando en un notebook puedes ver las funciones dentro de una biblioteca escribiendo el nombre-de-la-biblioteca. y despues Tab (la tecla tab). Por ejemplo, escribe numpy. y la tecla tab para ver todas las funciones dentro de numpy.
Cuando analizamos datos, frecuentemente queremos analizar variaciones en datos estadísticos, como la precipitación mensual máxima por año o la precipitación promedio en todos los meses de mayo. Una forma de hacer esto es crear un nuevo arreglo temporal de datos y después calcular sobre ese arreglo:
anio_2010 = data[0, :] # 0 en el primer eje (filas), y todo en el segundo eje (columnas)print('maximum inflammation for patient 0:', numpy.max(patient_0))
print('La precipitación mensual máxima (mm) en 2010 fue:', numpy.max(anio_2010))
Todo lo que sigue del símbolo "#" es un comentario que Python ignora. Los comentarios ayudan a los programadores a dejar notas para explicar algo dentro del código para ellos mismo o para otros programadores.
En verdad no necesitamos guardar la fila seleccionada en una variable. Podemos combinar la selección con el llamado a la función en una sola línea:
print('La precipitación mensual máxima (mm) en 2010 fue:', numpy.max(data[0,:]))
Imagina que necesitamos la máxima precipitación en cada año (diagrama de la izquierda) o el promedio de precipitación por cada mes (derecha). Como se muestra en el diagrama, queremos realizar operaciones a lo largo de los ejes:
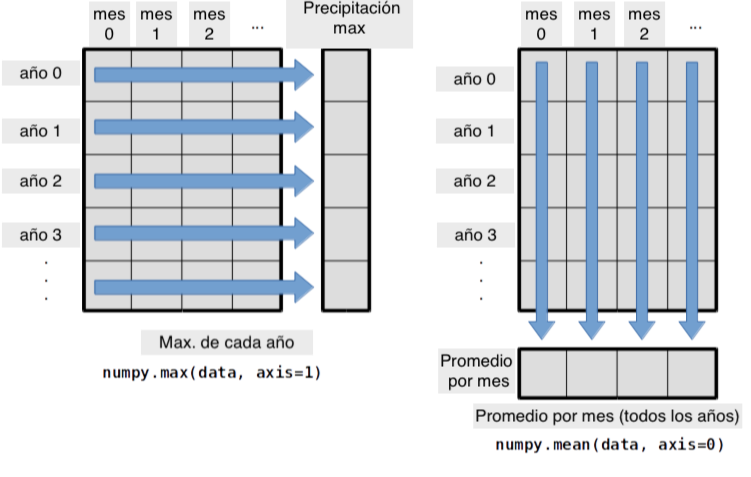
La mayoría de las funciones que usan arreglos como input nos permiten especificar a lo largo de qué eje queremos hacer la operación. Si pedimos el promedio sobre el eje 0 (filas en nuestro ejemplo 2D), tenemos:
print(numpy.mean(data, axis=0))
Podemos checar rápidamente cuáles son las dimensiones del output:
print(numpy.mean(data, axis=0).shape)
La expresión (12,)nos dice que tenemos un vector de 12x1, así que esto es la precipitación promedio por mes (el promedio de precipitación para toodos los eneros, febreros, etc).
Si tomamos el promedio sobre el eje 1 (columnas), obtenemos:
print(numpy.mean(data, axis=1))
Que es la precipitación promedio para cada año.
Practica lo que aprendiste¶
Podemos tomar rebanadas o selecciones de strings:
elemento = 'oxigeno'
print('Los primeros tres caracteres:', elemento[:3])
print('Los últimos tres caracteres:', elemento[4:7])
¿Cuál es el valor de
elemento[:4]y deelemento[4]?¿Qué es
elemento[-1]y deelemento[-2]?
print(elemento[:4], elemento[4])
print(elemento[-1], elemento[-2])
- Explica qué hace
elemento[1:-1]
print(elemento[1:-1])
elemento[1:-1] selecciona la rebanada que va desde el elemento 1 (x) hasta el penúltimo (n)
Los arreglos se pueden apilar (stack en inglés) uno sobre otro usando las funciones de NumPy vstacky hstack para apliar en la vertical y horizontal, respectivamente.
A = numpy.array([[1,2,3], [4,5,6], [7, 8, 9]])
print('A = ')
print(A)
B = numpy.hstack([A, A])
print('B = ')
print(B)
C = numpy.vstack([A, A])
print('C = ')
print(C)
- Escribe código adicional que rebane la primera y última columna de
A, y las apile en un arreglo de dimensiones 3x2. Usa el comandoprintpara que puedas verificar tu solución.
D = numpy.hstack((A[:, :1], A[:, -1:]))
print('D = ')
print(D)
Aqui hay un truquito. Cuando tenemos un arreglo de 1 dimension (vector), por default la dimensión 1 se quita. Eso quiere decir que A[:,0] es un arreglo de 1 dimensión por lo cual no se apliará como queremos. Para preservar las dos componentes de las dimensiones, el índice mismo debe ser un a rebanada. Por ejemplo, A[:,:1]regresa un arreglo de dos dimensiones con una dimensión de 'dummy' (un vector).
print('las dimensiones de A[:,0] son:', numpy.shape(A[:,0]))
print('A[:,0] es: ', A[:,0])
print('las dimensiones de A[:,:1] son:', numpy.shape(A[:,:1]))
print('A[:,:1] es: \n ', A[:,:1])
2.4 En resumen¶
- Importa bibliotecas usando
import nombre-de-la-biblioteca. - Usa la biblioteca
numpypara trabajar con arreglos en Python. - La expresión
arreglo.shapete da las dimensiones del arreglo. - Usa
arreglo[x, y]para seleccionar un elemento de un arreglo 2D. - Los índices de los arreglos empiezan en 0, no en 1.
- Usa la notación
min:maxpara especificar una "rebanada" que incluya desde el índiceminhastamax-1. - Usa
# algo de textopara agregar comentarios en tus programas. - Usa
numpy.mean(arreglo),numpy.max(arreglo) ynumpy.min(arreglo)para calcular estadística simple. - Usa
numpy.mean(arreglo, axis=0)onumpy.mean(arreglo, axis=1)para calcular promedios sobre un eje específico.
3. Visualización de datos tabulares¶
La visualización de datos requiere una lección entera, pero hoy podemos explorar algunas funciones básicas de la biblioteca matplotlib. No hay una biblioteca "oficial" para graficar pero matplotlib es el estándar. Primero, importemos el módulo pyplot de matplotlib y usemos dos funciones para crear y mostrar un mapa (heat map) de nuestros datos:
import matplotlib.pyplot as plt
image = plt.imshow(data)
plt.show()

Los pixeles azulosos representan valores bajos y los más amarillos representan valores altos. Podemos ver que la precipitación es mayor en los meses de verano (5-9 del eje x). Veamos la precipitación mensual promedio de todos los años:
prom_precip = numpy.mean(data, axis=0)
prom_plot = plt.plot(prom_precip)
plt.show()

Aqui pusimos la precipitación mensual promedio a lo largo de todos los años en la variable prom_precip y luego le pedimos a matplotlib.pyplot (plt) que creara y mostrara una gráfica de líneas de esos valores. El resutado muestra un incremento de la precipitación en los meses de verano. Veamos otras estadísticas:
max_plot = plt.plot(numpy.max(data,axis=0))
plt.show()

min_plot = plt.plot(numpy.min(data,axis=0))
plt.show()

3.1 Grupos de gráficas¶
Podemos agrupar gráficas similares en una sola figura usando subgráficas. El script o progama siguiente usa varios comandos que no hemos visto. La función plt.figure()crea el espacio para una figura vacía en donde pondremos nuestras gráficas. El parámetro figsizele dice a Python de qué tamaño será la figura. Cada subgráfica se colocará en la figura usando el método add_subplot. add_subplot toma 3 parámetros. El primero denota cuántas filas de gráficas habrá en total, el segundo cuántas columnas y el último denota que a subgráfica hace referencia nuestra variable (derecha a izquierda y de arriba hacia abajo). Cada subgráfica se guarda en una variable distinta (axes1, axe2s, axes3). Una vez que se crea una subgráfica, se puede agregar título y numbres a los ejes usando set_xlabel(),set_ylabel(), etc.
# Este es un script completo - una unidad que importa las bibliotecas,
# lee los datos del archivo txt, calcula estadística y
# grafica los resultados
import numpy
import matplotlib.pyplot
data = numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
fig = matplotlib.pyplot.figure(figsize=(10.0, 3.0))
axes1 = fig.add_subplot(1, 3, 1)
axes2 = fig.add_subplot(1, 3, 2)
axes3 = fig.add_subplot(1, 3, 3)
axes1.set_ylabel('promedio')
axes1.plot(numpy.mean(data, axis=0))
axes2.set_ylabel('max')
axes2.plot(numpy.max(data, axis=0))
axes3.set_ylabel('min')
axes3.plot(numpy.min(data, axis=0))
fig.tight_layout()
matplotlib.pyplot.savefig('precipitacion.png')
matplotlib.pyplot.show()

fig.tight_layout() le da espacio suficiente a las gráficas dentro de la figura para que no queden aplastadas. La llamada a savefig guarda la figura como un archivo gráfico que se puede usar en otros documentos, por ejemplo para ponerlo en sus reportes ;-)
El formato del archivo lo determina matplotlib automáticamente a partir de la extensión en el nombre que le dimos al archivo. En el programa anterior es PNG porque usamos el nombre 'precipitación.png', pero se puede usar PDF, SVG, JPG, EPS, etc.
Ahora prueben ustedes¶
Crea una gráfica de la desviación estándar de la precipitacion mensual a lo largo de todos los años (axis=0). Agrega nombres a los ejes.
Modifica el progama anterior para que los límites de los ejes sean exactamente de 0 a 11 en x. Usa la función set_xlim(min, max) para lograrlo.
Modifica el progama anterior para que la figura muestre 3 subgráficas una encima de la otra en lugar de una a lado de la otra.
- Gráfica de desviación estándar:
import numpy
import matplotlib.pyplot
data = numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
fig = matplotlib.pyplot.figure(figsize=(4.0, 3.0))
axes1 = fig.add_subplot(1, 1, 1)
axes1.set_ylabel('desviación estándar (mm)')
axes1.set_xlabel('mes')
axes1.plot(numpy.std(data, axis=0))
fig.tight_layout()
matplotlib.pyplot.show()

2 y 3: Creo que había dos formas de interpretar "una gráfica encima de la otra", así que les dejo las dos soluciones:
Solución 1:
# Este es un script completo - una unidad que importa las bibliotecas,
# lee los datos del archivo txt, calcula estadística y
# grafica los resultados
import numpy
import matplotlib.pyplot
data = numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
fig = matplotlib.pyplot.figure(figsize=(4.0, 9.0))
axes1 = fig.add_subplot(3, 1, 1)
axes2 = fig.add_subplot(3, 1, 2)
axes3 = fig.add_subplot(3, 1, 3)
axes1.set_ylabel(' precipitación promedio (mm)')
axes1.plot(numpy.mean(data, axis=0))
axes1.set_xlim(0,11)
axes1.set_xlabel('mes')
axes2.set_ylabel('precipitación max (mm)')
axes2.plot(numpy.max(data, axis=0))
axes2.set_xlim(0,11)
axes2.set_xlabel('mes')
axes3.set_ylabel('precipitación min (mm)')
axes3.plot(numpy.min(data, axis=0))
axes3.set_xlabel('mes')
axes3.set_xlim(0,11)
fig.tight_layout()
matplotlib.pyplot.savefig('precipitacion.png')
matplotlib.pyplot.show()

Solución 2:
# Este es un script completo - una unidad que importa las bibliotecas,
# lee los datos del archivo txt, calcula estadística y
# grafica los resultados
import numpy
import matplotlib.pyplot
data = numpy.loadtxt(fname='precip_mensual_estacion01.csv', delimiter=',')
fig = matplotlib.pyplot.figure(figsize=(6.0, 5.0))
axes1 = fig.add_subplot(1, 1, 1)
axes1.set_ylabel('precipitación (mm)')
axes1.plot(numpy.mean(data, axis=0), label='promedio ')
axes1.plot(numpy.max(data, axis=0), label='max ')
axes1.plot(numpy.min(data, axis=0), label='min')
axes1.set_xlim(0,11)
axes1.set_xlabel('mes')
axes1.legend()
fig.tight_layout()
matplotlib.pyplot.savefig('precipitacion.png')
matplotlib.pyplot.show()
